We live in an era of digital technology where information is key. The vast amounts of data on the internet have become an area of study we now call "Big Data". So what exactly is big data, and how is it useful?
"Big Data" refers to large sets of data generated by various sources. Different internet sites, web apps, and company information generate vast data. These large amounts of data can be structured or unstructured.
Impact of Big Data
How can "Big Data" impact any business? Let us see...
-
Businesses generate large amounts of data. They vary in user behavior, purchases, and traffic. If a company wants to improve its services, it can use client data to study patterns.
-
Custom-based services are provided to clients by studying the client data. A company is able to provide market-specific services to clients and improve delivery.
-
Big data analytics also improve the efficiency of the existing processes. Large amounts of data are processed to identify hidden patterns and correlations. The results affect production, services, distribution, and workforce levels.
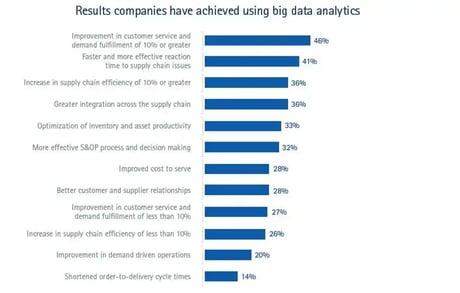
Source: forbes.com
When big data has such an impact on businesses, a company will want to hire the best resources it can get (also consider checking out this perfect parcel of information for a data science degree). It is necessary to have the relevant skills that will add value to your career in the long run.
top skills
We present the top skills you must have to get that high-paying big data job. So those of you who aspire for a big data job, wait for no further and read on…..
1. SQL(Structured Query Language):
Even though this database technology is decades old, it is a useful application in big data. Learning SQL will enable you to use queries to access distributed data seamlessly.
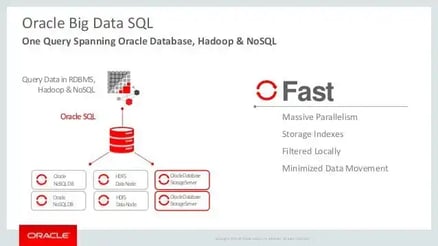
An example is the Oracle Big Data SQL which enables you to run complex SQL statements to get insights. It easily integrates data with existing systems with secure and fast access to data.
To learn more about SQL, please visit: https://www.oracle.com/database/big-data-sql/index.html
2. Python Programming:
Programmers prefer Python as it has a simple syntax and is easy to learn. It has a wide set of data libraries and integrates easily with web applications. It is easy to build scalable applications which help process large data sets.
Features of Python programming:
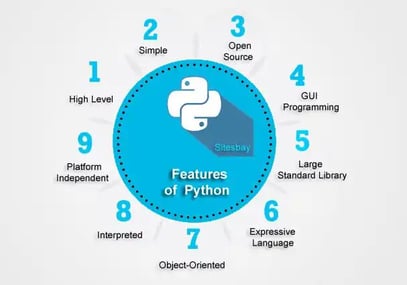
Source: sitesbay.com
To learn more about Python, please visit: https://www.python.org/about/gettingstarted/
3.Java Programming:
Open source software frameworks such as Hadoop are written in Java. Programming in Java is a basic skill required when working with large datasets. Java Virtual Machines (JVM) are used to run operations in the big data ecosystem (also consider checking out this career guide for data science jobs).
Features of Java language:

Source: safaribooksonline.com
To learn more about Java, please visit: http://introcs.cs.princeton.edu/java/10elements/
4. R programming:
This language is used to visualize and analyze data. Data mining and statistical computing find applications of R in creating reports. It is supported by the R Foundation and is helpful in creating graphics for data analysis.
Source: elearningindustry.com
To learn more about R Programming, please visit: https://www.r-project.org/about.html
5. SAS(Statistical Analysis System):
SAS was developed in the late sixties by the SAS institute. It has a 33 % market share in the area of advanced analytics. It is a statistical tool that provides solutions of high quality. Distributed processing of data is faster using SAS and helps in getting quick insights.
Source: linkedin.com
To learn more about SAS, please visit: https://support.sas.com/training/index.html
6. Apache Hadoop:
Hadoop is an open-source cluster computing software framework. It enables the storage of large amounts of data and fast processing. It is capable of handling multiple requests at a time to deliver insights. It provides flexibility for processing unstructured data and has high scalability.

Source: hadoop.apache.org
To learn more about Apache Hadoop, please visit: http://hadoop.apache.org/
7. Apache Hive:
Hive is an open-source data warehousing language for analyzing data in the Hadoop system. It has an SQL-like interface to query data stored in the database. Hive has three main functions, namely, data summary, query, and analysis.

Source: slideshare.net
To know more about Apache Hive, please visit: https://hive.apache.org/
8.MapReduce:
MapReduce is a parallel processing software framework. It is used to write applications for processing large structured and unstructured data.
MapReduce has two functions for work. The Map function forms a master node that takes inputs and distributes work to other nodes in a cluster. After the processing is complete, it needs to form a report.
The Reduce function takes the output and reduces the results from all nodes into a report or query.

Source: mssqltips.com
To learn more about MapReduce, please visit: https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
9. Apache Pig:
Pig is an open-source platform for processing data stored in the Hadoop ecosystem. It comes with a built-in compiler for MapReduce programs to perform data extraction. It uses a high-level language called Pig Latin to execute Hadoop tasks.
There is no need to maintain any Hadoop cluster or write programs in MapReduce. The Pig Latin language can be used to execute tasks in the Hadoop file system.
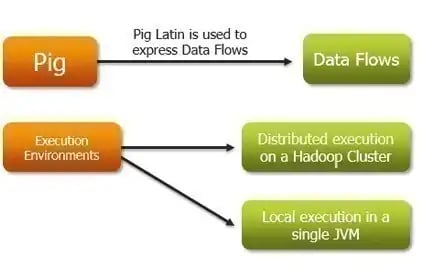
Source: pocfarm.wordpress.com
To know more about Apache Pig, please visit: https://pig.apache.org/
10. Apache Spark:
Apache Spark is an open-source cluster computing framework. It is a fast, in-memory data processing engine with multi-program APIs. The languages can be Java, Python, or Scala. It also has libraries that enable it to manage tasks for SQL, machine learning, and data streaming.
Spark is often described as a data access engine. It provides faster data processing using distributed systems along with cluster managers.
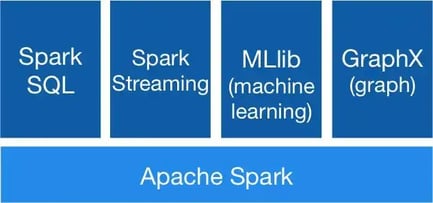
Source: spark.apache.org
To know more about Apache Spark, please visit: http://spark.apache.org/
11. Data Visualization:
Reports of data can be lengthy and verbose at times. When you face such a case, it will be useful if data is presented in a graphical or pictorial format. If data is shown in a visual format, it helps easily convey the concepts.
Data visualization plays a role in the decision-making process for product/service-oriented companies. It helps to identify areas for improvement and make informed decisions based on reports.
Source: smartsheet.com
Source: qlikblog.at
To know more about data visualization tools, please visit: http://www.tableau.com/ and http://www.qlik.com/us/
12.NoSQL:
NoSQL is a type of database that does not follow the rules of the commonly used relational databases. NoSQL stores large amounts of unstructured data and uses flexible data models for processing.
Relational databases use tables and schemas to retrieve data. NoSQL does not use the approach of traditional RDBMS methods. The benefits of NoSQL include flexible data models, scalability, availability, and superior performance.
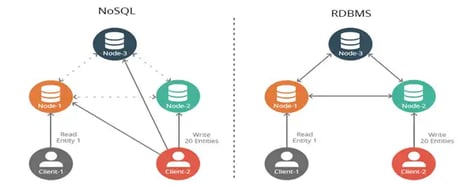
Source: intellipaat.com
To know more about NoSQL, please visit: https://www.mongodb.com/nosql-explained
13. Machine Learning:
Machine learning is a set of techniques and algorithms that can learn from data. These methods help identify hidden patterns and correlations in datasets.
Machine learning algorithms allow computers to search for hidden patterns in datasets. This technique allows computers to search for data without being specifically programmed.
These self-learning algorithms can process large amounts of data in a short span of time. Some of the popular machine learning methods are:
-
Supervised learning
-
Unsupervised learning
-
Semi-supervised learning
-
Reinforcement learning

Source: slideshare.net
To know more about machine learning, please visit: https://www.sas.com/en_us/insights/analytics/machine-learning.html
These are the must-have skills you should have when applying for a job in the field of big data. It will give you a competitive edge and ensure you land that high-paying job you always dreamt about.
Happy Learning!