One of the key sources of data for both organizations and researchers is the internet. While one could copy-paste relevant information from webpages and transfer it to excel sheets, CSV, and TXT files, it isn't feasible if larger data sets are required. So, how are larger data sets collected by Data Scientists from the internet?
One of the most frequent, and time-consuming tasks that Data Scientists have to perform is collecting data and cleaning it.
Web Scraping
While web-based data collection can be a challenging task via a manual approach, a lot of automated solutions have cropped up courtesy of open-source contributions from software developers.
The technical term for this is web scraping or web extraction. With the use of automated solutions for scraping the web, data scientists can retrieve hundreds, thousands, and even millions of data points. This is highly efficient and saves not just time but also is extremely accurate as it eliminates clerical errors.
Disclaimer: Though web scraping is now becoming an essential part of our data acquisition technique, protecting ourselves from piracy or unauthorized commercial use of extracted data is required.
In this article, we shall explore data scraping with the help of Beautiful Soup (also consider checking out this perfect parcel of information for a data science degree).
What is beautiful soup?
Since 2004, Beautiful Soup has been rescuing programmers to collect data from web pages in a few lines of scripts. Beautiful soup is one of the most widely-used Python libraries for web scraping.
As mentioned in their website, beautiful soup can parse anything we give it. Most commonly, it is used to extract data from HTML or XML documents. It is a simple and easy tool to use. It hides away a lot of the cumbersome complications that would arise if one were to go. However, methods required conceptual understanding. Hence, it is a premier tool among data aficionados to scrape the web.
You may also like: Top 45 HTML 5 Basic Interview Questions and Answers You Must Prepare
Essential Steps Before Scraping
Let’s scrape an HTML table from Wikipedia. You will need a basic understanding of HTML DOMs and Python.
Step 1
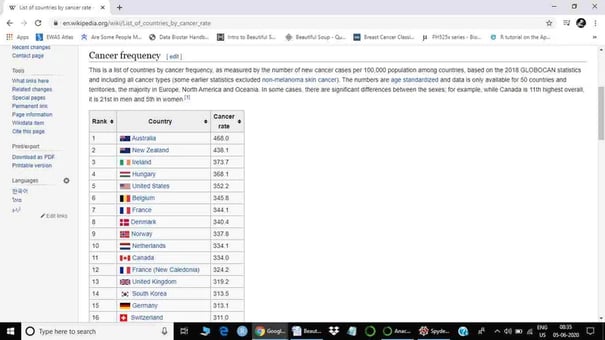
The first step of web scraping is to find a table we want to scrape, which means figuring out the table and web page we want to scrape. As a research scientist, I would like to give an example of web scraping from a list of countries by cancer rate from Wikipedia (https://en.wikipedia.org/wiki/List_of_countries_by_cancer_rate).
Step 2
Now we are ready to scrape a web page, but do we have all the pivotal tools to scrape it? As I mentioned earlier, we are using python to scrape the web page. I will use Google Colab as the python platform. Google Colab comes with all the required python libraries, so you do not have to worry about any installations. Another important platform for python is Jupyter notebook or Spyder using Anaconda. Anaconda also comes with many python libraries, including Beautiful Soup. However, we may have to download a few libraries in Anaconda. If you are using any other software for python programming, then you have to download all packages required for Web Scraping or any other analysis.
The external parser is required to parse the HTML files, as the beautiful soup package is incapable of parsing it. Three important parsers are supported by the beautiful soup package:
- python built-in parsers (html.parser),
- lxml, and
- html5lib.
We have to install lxml and html5lib as they are not in-built libraries. However, if you are using Google Colab or Anaconda, you do not have to install it. lxml is the only XML library and ranked best by the beautiful soup. Hence, we will use lxml for parsing.
Installation
Though the installation of packages is straightforward, it also depends on the operating system you are using, such as windows, mac, or Unix. Let’s see how to install required packages for web scraping using beautiful soup in windows. Skip thiss step if you are using Google Colab or Anaconda. Commands required to install packages are given below:
- Installing Beautiful library
pip install beautifulsoup4 - Installing lxml library
pip install lxml - Installing pandas
pip install pandas
Step 3
All required libraries are now installed. Before moving ahead let’s check the table we want to scrape. First right-click on the table. Now it will show us an ‘inspect’ option.
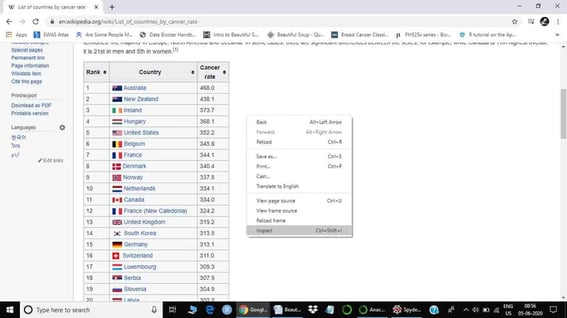
The next step is to click the inspect option. It will open the HTML document of that specific web page.
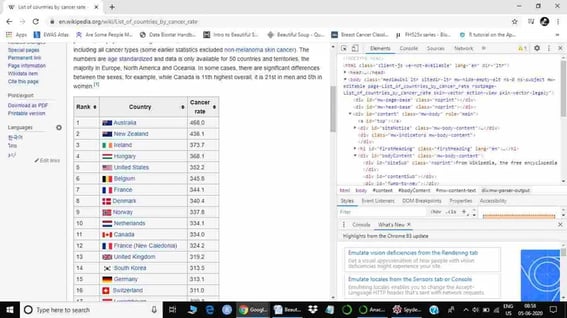
Once the HTML document is open, we have to check all information regarding the table we are going to scrape.
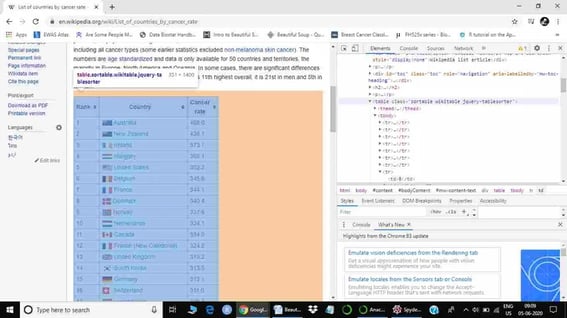
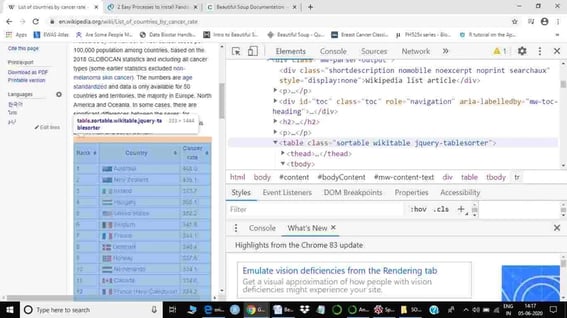
Here, the class of the table is ‘sortable wikitable’, highlighted in blue color in the HTML document. When we put our cursor on the table, it should also highlight the table (only table) we want to scrape. If it does not highlight the table, it means that we are exploring the wrong table. Once we know the class of our table, we can start scraping (also consider checking out this career guide for data science jobs).
Important steps for web scraping
Here, I am going to show you some required steps to scrape this table. Different tables of web pages may have different challenges. Hence, a good knowledge of HTML, beautiful soup and python is essential. We should get more information about the beautiful soup from the link provided below.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/.
Let’s move and scrape the first table of the Wikipedia page.
Step 1
Like most data science projects, the first step is to import the tools (libraries) necessary.
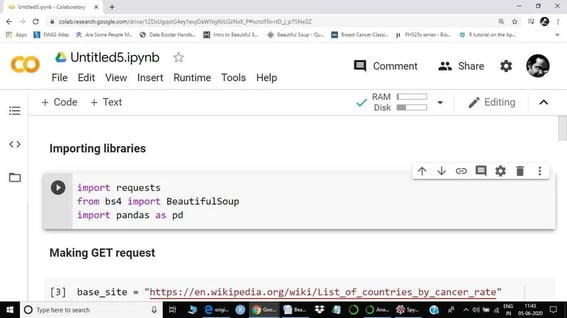
Step 2
Step 2 of web scraping is a GET request. But, before we get a request, we have to save the URL of the webpage with a name. Here, I saved it as a base_site. On a web server, we mostly communicate through HTTP requests. GET is one of the most popular request types. Our get request is saved in r, which actually represents the response.
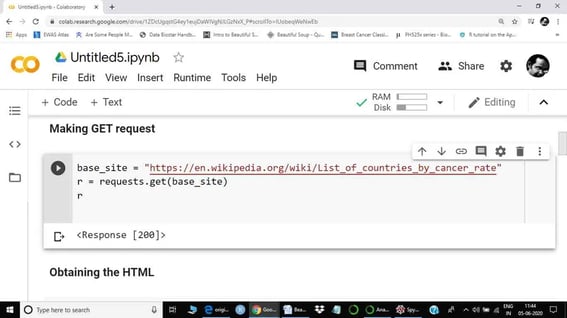
If you get a response code 200, like above, that means the operation was successful. If you get 404, that means that the page was not found.
Step 3
The next step is to obtain HTML from the response (r).
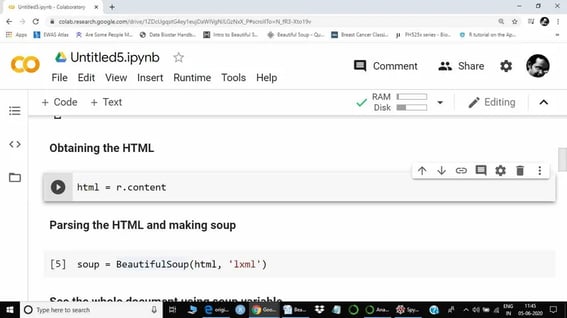
Step 4
In this step, we will call a beautiful soup function to extract the data from the HTML document. LXML will be used to parse the HTML file. Extracted data will be saved in the soup variable as assigned.
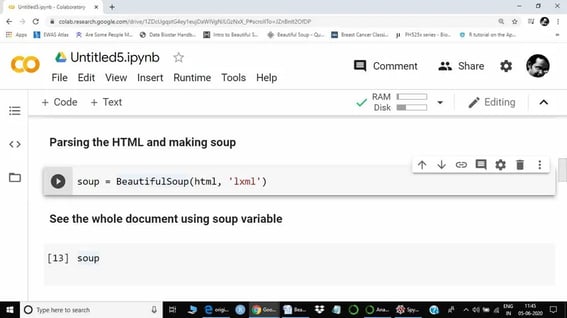
Step 5
Step 5 is basically data exploration using a beautiful soup function. We are just going to see a few functions as required for current web scraping. However, I would suggest you explore more functions of beautiful soup from the above-provided link, as each web table or web text may present a different challenge. The next step is to call the soup variable. Here, soup represents the whole HTML document.
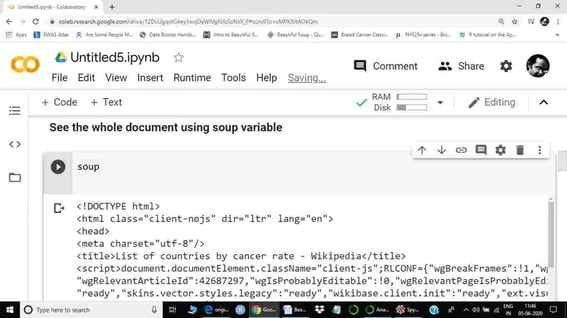
Step 6
.find() and .find_all() methods are the most popular methods to explore a newly created soup. They can be used in a variety of ways. Note that .find() gives only the first result from a line from a query, while .find_all() is used to extract all the queries from the page.
In this step, I am using the .find() function to extract the table. The class of the table we are scraping is the sortable wikitable, as this information is obtained from the HTML file above.
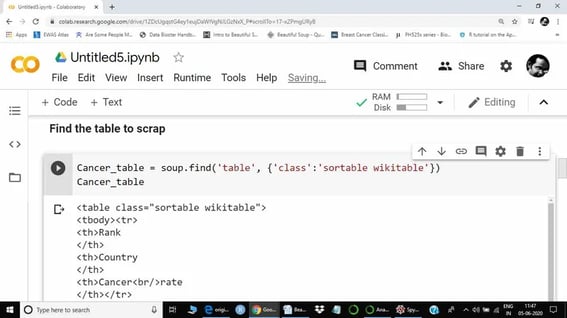
Now, we can see all three columns: Rank, Country, and Cancer rate.
Step 7
If you look at the Wikipedia page again, you can see that countries in the "Country" column are actually links. We can also confirm it using anchors:
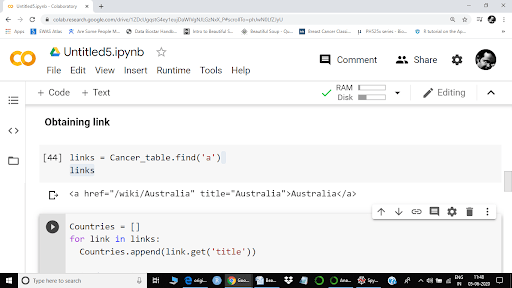
Here ‘a’ represents anchor and ‘href’ suggests there is a link. However, as I have used the .find() method, we are seeing only the first link. To extract all links, we will use .find_all() method.
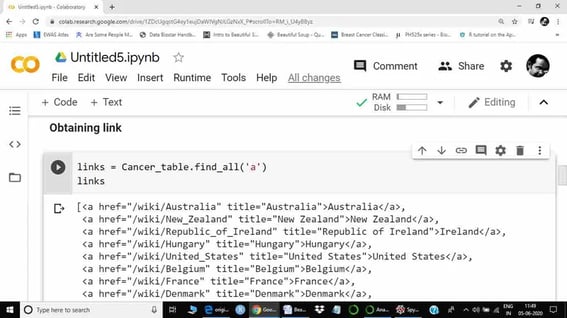
Now we can see the links for all countries. The next step is to create a list of all countries. Hence, we will use a ‘for’ a loop. Get function will be used to retrieve specific information, here using the title (title = country name).
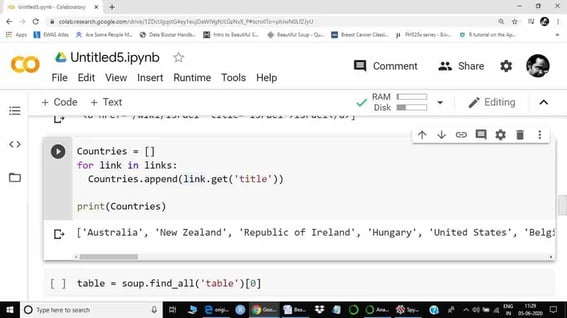
Now, our list containing country names as elements are ready.
Step 7.1
This step is again part of step 7, as we are going to extract the Cancer rate column. Earlier, I had called the .find() method to create our table. Now we will use .find_all() method.
You may also like: Top 50 Python Interview Questions with Answers for Freshers
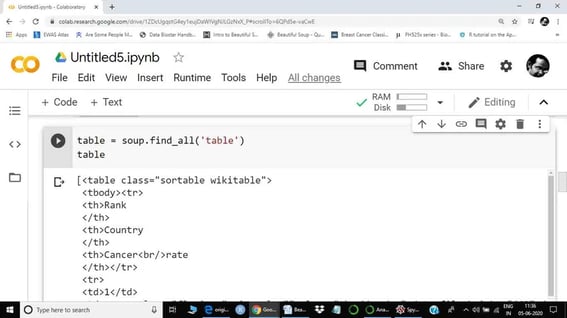
As we can see, there are different tags inside a table.
- th = Table heading
- tr = Table row
- td = Table data cell
After exploring the ‘table’, we are sure that the first table is the table which we are going to scrape. Hence we will use index[0] to retrieve it.
Reminder: there might be more than one table. Hence, it is important to figure out the item number of the relevant table. Otherwise, the wrong indexing will produce the wrong results.
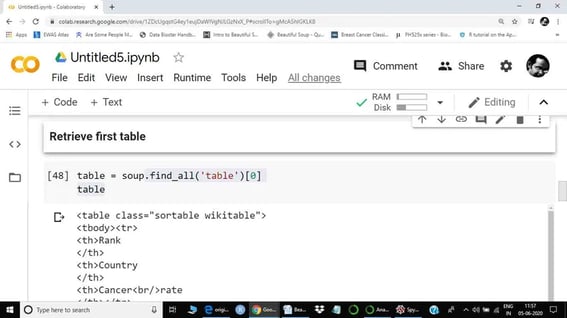
Now the table contains all the required information for table 1 (List of countries by cancer rate). The next step is to check the first row of the table using index[0]. Mostly the first row of a table is a header name.
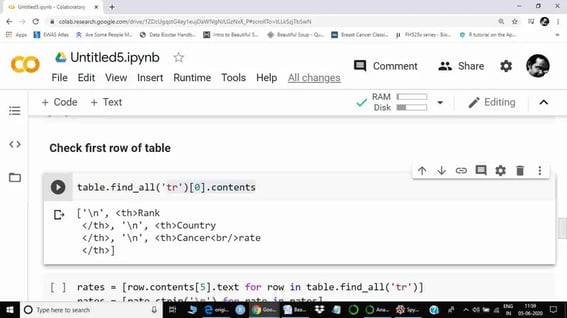
From here, we can see that the Cancer rate is the 6th element. Indexing in python starts from 0, hence we will use the 5th index to extract information from the Cancer rate column.
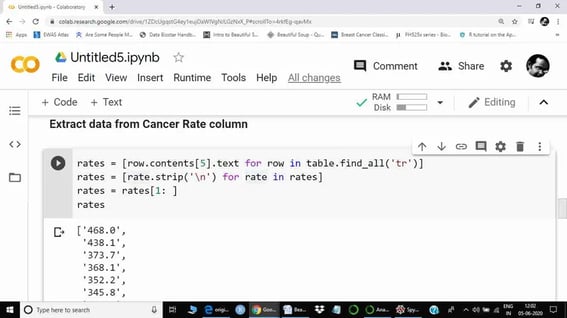
A loop was used to extract information from all elements. .strip() function was used to strip \n from each element. The first element was the column name, hence we excluded the first element to match it with the country list. The obtained data is a string here, rather than float.
The next step is to convert the string into the float.
Here, we called the float method to convert strings into the float. As there are many elements in the rate list, hence a ‘for’ loop was called to convert all elements into the float.
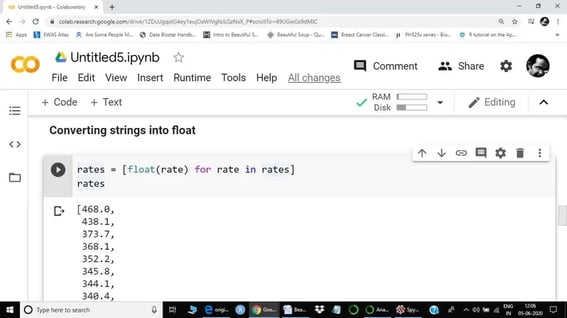
Now both lists are ready. The next step is to merge these lists together and convert them into a data frame. We are now done with beautiful soup. From here onwards, we will use the panda's library to convert lists into a data frame.
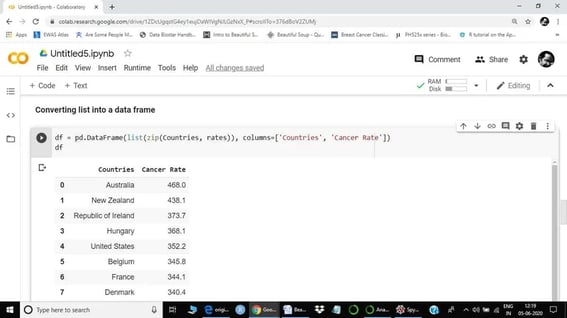
In this step, we first zipped both lists and then converted it into a data frame using pandas. We also assigned the column names here. The whole data is saved in a df variable. Our newly created data frame is ranked by cancer rate, hence I did not add that specific row. Please do not confuse with indexing.
The next step is to save our data frame as excel, a CSV, or as a text file. We can do any analysis as required using a newly created data frame. However, it is always a good idea to save the final cleaned file, as we may have to provide it to someone.
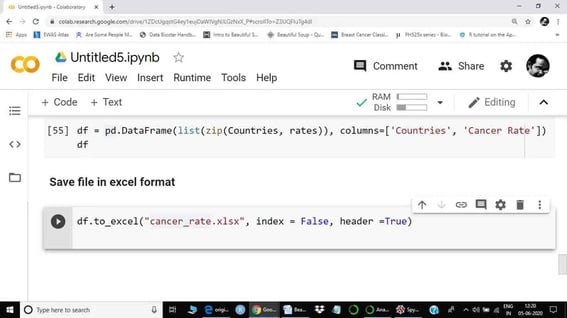
Again, I used pandas to save my file as an excel sheet. Note that I excluded the index from the file.
Conclusion
Beautiful soup is rather easy to use, and to make full use of it, becoming familiar with its various methods is essential. Each webpage comes with its own challenges. Hence, the same function might not be useful in all scenarios.
There are a few roadblocks whilst scraping the web, such as setting the “User-agent” request header, setting cookies, and excessive requests. It is therefore useful to understand the structure and layout of HTML documents to figure out links, paragraphs, tables, etc., so that you can locate and scrape for the correct element. Combining this with NumPy and Pandas is necessary to configure, store and structure the data that is being retrieved. Combine all of these key spices to make your beautiful soup!