Sentiment Analysis is the process of computationally determining whether a piece of content is positive, negative or neutral. It is also known as Opinion Mining.
Why Sentiment Analysis?
Sentiment Analysis is mainly used to gauge the views of public regarding any action, event, person, policy or product. It has become a very potent weapon even for politicians to assess the public reaction over their statements (also consider checking out this perfect parcel of information for data science degree). These days Opinion Mining has reached an advanced stage where several outcomes can be predicted using large datasets and machine learning etc.
However, in this post, we will restrict ourselves to extracting 1000 tweets about Narendra Modi, Prime Minister of India and do a sentiment analysis and calculate the percentages of Positive, Negative and Neutral Views.
Tools & Libraries Required
Tweepy:
Tweepy is an easy to use Python library for accessing the Twitter API
We will be using Tweepy to extract tweets from Twitter Stream.
You can install tweepy using the command
pip install tweepy
TextBlob:
TextBlob is a Python (2 and 3) library for processing textual data. It provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
You can install textblob using the command.
pip install textblob
You will also need to the Natural Language ToolKit.
python -m textblob.download_corpora
Extraction of Tweets
Registering App with Twitter
To extract tweets from Twitter Stream using API, we first need to register an App with Twitter. Go to TwitterApps and click on New App after signing up.
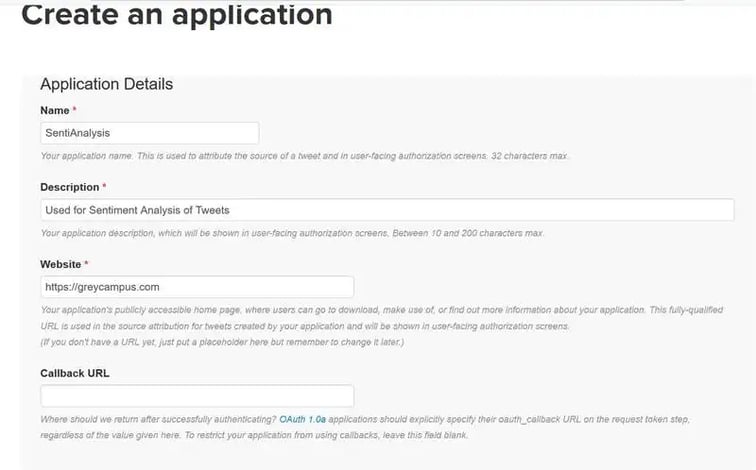
You can leave the Callback URL empty. Agree to the Developer Conditions and select Create App.
We need the Secret Keys and Access Tokens for the API to work (also consider checking out this career guide for data science jobs). Please Click on “Keys and Access Tokens” Tab. You will find Consumer Key and Consumer Secret. Note them down.
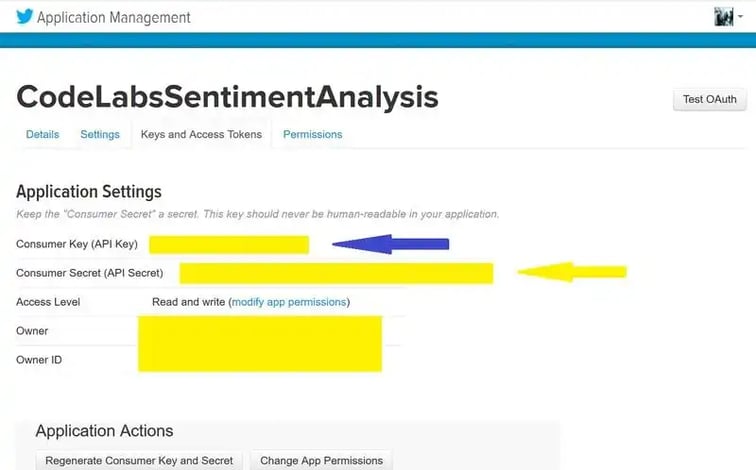
Now, we need to create Access Tokens for our Account. Click on “Create my access token”
And then note down the “Access Token” and “Access Token Secret”
Now we are ready to retrieve tweets from Twitter Stream. Let us extract a few tweets using the above details
Retrieve Tweets
Let us write a class TwitterClient for extracting Tweets. We will initialize our connection in the constructor using the code
Run the program at the terminal – you will be finding 10 tweets that contain “Narendra Modi”
- We have defined a TwitterClient class that handles all interaction with Twitter API
- We use a __init__ function to handle the authentication.
- We are retrieving the tweets using the get_tweets function
Prepare for Natural Language Parsing
However, if you observe, the tweets contain external links, a lot of white spaces etc. For our Opinion Mining, we do not need all of it. Let us remove all external links, special characters using a regular expression. You can read more about regular expressions here.
Let us add one function trim_text which handles the cleaning up of the tweet.
def trim_tweet(self, tweet):
Now instead of directly assigning into parsed_tweet, we will assign
parsed_tweet['text'] = self.trim_tweet(tweet.text)
Run the program again, you will find that Tweets are trimmed and shortened.
Now let us proceed to the most important part of the exercise – Opinion Mining using TextBlob
Opinion Mining Using TextBlob
When we create a TextBlob object, the following processing happens:
- Tokenize the tweet – The tweet will be split into constituent words.
- Remove stop words from the tweet, which are not relevant for the mining. For example, words like am, are etc.
- Parts of Speech Tagging is the most important activity done by TextBlob object. Here, adjectives, adverbs etc. which are relevant are tagged to the keyword.
- Passing the processed tokens to Sentiment Classifier which will return a value between -1.0 and 1.0
Let me explain a bit more about how the Sentiment Classifier works:
- TextBlob uses a large Movie Review Dataset which is pre-classified as positive and negative (Here's the perfect parcel of information to learn data science).
- TextBlob trains using the Naive Bayes classifier to determine positive and negative reviews.
- For the training, we can change the data set – but that is for another project😊
- Now, the sentiment classifier essentially calculates the polarity of tokens between -1.0 and 1.0
- -1.0 is negative, 0.0 is neutral and 1.0 is positive
Now that we understand the modus operandi of Opinion Mining let us write a function get_tweet_sentiment
def get_tweet_sentiment(self, tweet):
# create TextBlob object of passed tweet text
analysis = TextBlob(self.trim_tweet(tweet))
# set sentiment
if analysis.sentiment.polarity > 0:
return 'positive'
elif analysis.sentiment.polarity == 0:
return 'neutral'
else:
return 'negative'