Artificial intelligence sometimes seems like a magic bullet, a one-size-fits-all solution. In reality, machine learning algorithms are more like a toolbox. One might be fine-tuned for speech recognition. Another works for self-driving car perception, and a third creates stylized art. So which algorithms fit well for each task? Below are a few types of machine learning algorithms that every machine learning engineer must know.
Image Processing - Convolutional Neural Networks
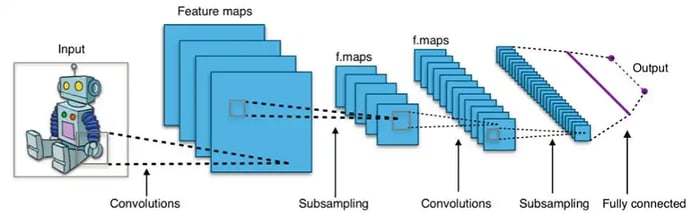
Source: https://adventuresinmachinelearning.com/convolutional-neural-networks-tutorial-tensorflow/
CNNs are the workhorse of object recognition. They are composed of several layers of abstraction. For example, the first layer of CNN acts as a simple edge detector. It captures vertical lines, horizontal lines, diagonal lines, and various colors. These simple features are then composed together to create complex shapes, such as the triangular ear of a cat. Google Street View, for example, automatically identifies house numbers from images. The strength of CNNs is translation invariance, which means it doesn't matter where an object is located in the image. A cat in the top left corner is the same as a cat in the top right corner. Yet CNNs are not rotation invariant; they will struggle to classify an upside-down cat. We handle this via random rotations, which means that training set images are sometimes flipped 30, 90, or 180 degrees. With data augmentation, CNNs now classify animal species better than humans can!
Sequential Data - Recurrent Neural Networks
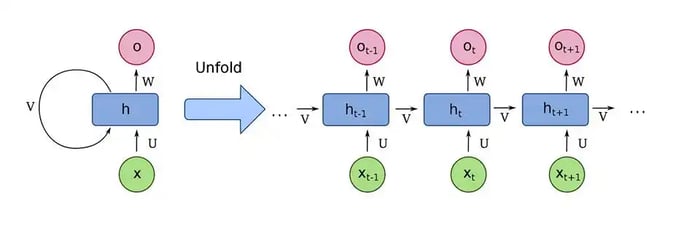
Source: https://en.wikipedia.org/wiki/Recurrent_neural_network
RNNs work well at speech recognition and time series prediction. Have you ever had to say, "Hey Siri" or "Ok Google" every time you make a command? Well, RNNs solve a fundamental problem in most ML algorithms - the lack of memory. Context is crucial for inference. For example, the command “Give me directions there” is useless without knowing what preceded it. Was it “What’s the best restaurant in town?” Was it "Where does my aunt live?" The strength of RNNs is their representational capacity. Their weakness is being notoriously difficult to train. Recently, 1-dimensional convolutions have shown improved results over time-series data (also consider checking out this career guide for data science jobs).
You may also like: Artificial Intelligence and Machine learning: How are they related?
Feature Extraction - Principal Component Analysis
PCA is a visualization strategy for high-dimensional data. People can only visualize two or three dimensions at once. PCA decorrelates and rescales variables, selecting the most important ones to plot first. This is sometimes called "centering and whitening" in ML preprocessing.
Nonnegative matrix factorization is a variant of PCA where each basis vector is nonnegative. In topic modeling, for example, we wish to extract the five main topics discussed in a speech. The bag-of-words approach is effective, counting the frequency of words in each sentence. A topic would be a unique combination of words, so the speech would be a combination of certain weighted topics. A topic can't contain negative words, thus we use NMF. Study Latent Dirichlet Allocation for more information.
Generating Data - Generative Adversarial Networks
Some data distributions are easy to generate, like a coin flip (Here's the perfect parcel of information to learn data science). Others are tough, like the distribution of all images of faces. How would you even write down a mathematical formula for generating faces? It’s intractable. Yet adversarial training pits two ML networks against each other. The generator creates synthetic images, and the discriminator distinguishes between real and synthetic. These two networks improve in tandem until synthetic faces are indistinguishable from the real thing. This process is adversarial training, used in fields such as video frame prediction.

Generating Data - Invertible Neural Networks
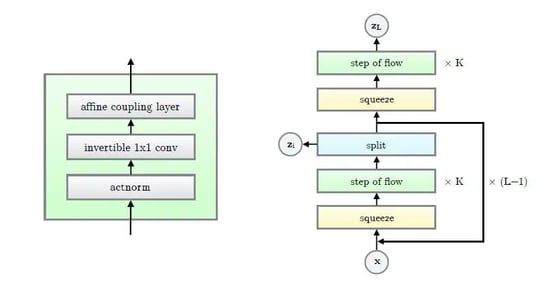
Source: https://arxiv.org/abs/1807.03039
Invertible neural networks also generate complicated data, but in a different way. The INN approach is much more mathematically principled. Through the change-of-variables formula, an INN maps a simple probability distribution to a complex one. For example, a multivariate normal could map to the distribution of faces. OpenAI recently published cutting-edge work in this field, entitled Glow. Its latent space interpolation is incredibly realistic. Glow enables fine-grained “feature selection” of skin color, hair color, even jawline sharpness.
Learning from Limited Labeled Data - Semi-Supervised Learning
In machine learning, obtaining labeled data can be expensive or infeasible. Semi-supervised learning (SSL) uses unlabeled data to augment limited labeled data. For example, look at the limited labeled data below. How would you classify the test point?
Now examine the limited labeled data in the context of the unlabeled data. It becomes obvious that there are two distinct clusters. One application of SSL is medical imaging, where we wish to identify cancerous cells in tissue scans. The training data required is not a single classification per image, but a pixel-by-pixel classification. On a high-resolution slide scan, that is more than a million! It’s rare to have more than a few hundred high-quality hand-labeled examples. Yet unlabeled medical images are abundant. If we can identify patterns in the unlabeled data and apply them to the limited labeled data, our algorithm will be more accurate (also consider checking out this perfect parcel of information for data science degree).
You may also like: Machine Learning for Dummies - A quick guide
Better A/B Testing - Thompson Sampling
Imagine that we’re optimizing Amazon’s search suggestions for books. We have known bestsellers and novels that appeal to a wide audience. We also have unknown books recently published. Some are bestsellers; some are flops. How should we learn which ones are hits and which ones are duds? The simplest form of this is A/B testing. Half of the website visitors see book A, half see B, and record the results. Yet imagine that book B is a total flop. If users had seen book A, they would have bought it. Instead, they saw book B and bought nothing. While we run the A/B test, 50% of potential revenue disappears! There is a better way to address this.
Enter Thompson sampling. This is a Bayesian approach, meaning that we take prior beliefs about which is better and update those over time. We start with wide statistical confidence intervals. As we gather more observations, the confidence intervals narrow until we are confident which book sells best. In the meantime, we sample the believed better products more often. Let me emphasize that. In Thompson sampling, we display our believed best option more frequently. If it's an incorrect belief, we discover this quickly and move on to more promising books. If that belief is correct, all the better. This method is an elegant solution to the exploration/exploitation question.
Conceptual Understanding - Graph Neural Networks
A graph means two different things, depending if the context is high school algebra or graph theory. In graph theory, a graph is a data structure containing nodes and edges. Picture a network of cities and roads connecting them. This map is a mathematical graph, where the cities are nodes and the roads are edges. Generally, nodes represent objects and edges represent object relationships. For example, a water molecule has hydrogen/oxygen atoms and as nodes, and covalent bonds as edges.
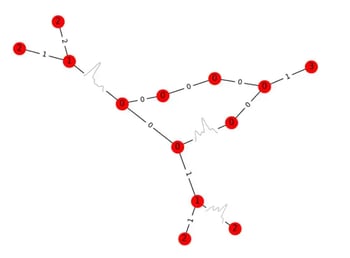
Source: https://arxiv.org/abs/1902.10042
Neural networks can compute functions over graphs. For example, imagine that Amazon Alexa hears the question: “Who plays point guard on the Utah Jazz?” Alexa leverages a knowledge graph or a set of facts and relations used to answer questions. It's important to know the relationship between “point guard” and “Utah Jazz”. In this case, a common link might be the concept “basketball team”. Then further inference can take place.
Hyperparameters - Bayesian Gradient-Free Optimization
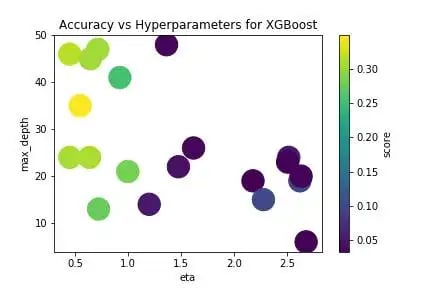
Anyone who has trained a deep neural network knows the pain of manually tweaking the learning rate. Then there are regularization parameters, batch normalization, and so on. Trial-and-error takes a huge amount of human time to test, wait, tweak, and repeat. Better methods for choosing them to include grid search, random search, and Bayesian search. Grid search tries a grid of various hyperparameter configurations. Random search tries random combinations within the grid and performs better than grid search. Bayesian optimization constructs a posterior probability distribution over the hyperparameter space. I recommend the powerful open-source library hyperopt to speed up your machine learning workflow.
Interpretable Models - Random Forest
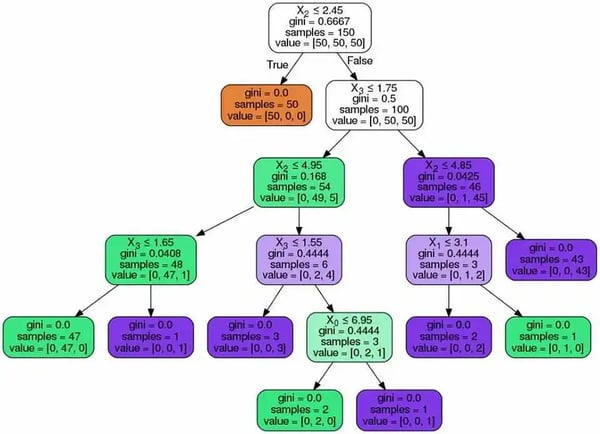
Machine learning is infamous for its black-box models. The relationship between inputs and outputs is quite opaque. Yet quality and stability are crucial in fields such as medicine and finance. They can handle numerical or categorical inputs and output classification or regression models. Best of all, its inference algorithm is a simple yes/no question at each branch. This is interpretable by domain experts. In almost any scenario, the random forest algorithm should be your first baseline.
Conclusion
Picking the right machine-learning algorithm makes all the difference. Check out libraries such as Pytorch and Scikit-learn. These libraries have sample datasets, visualizations, and everything you need to get started. Enjoy exploring!