

Related Topics
Hadoop is a 100% open-source Java‐based programming framework that supports the processing of large data sets in a distributed computing environment. To process and store the data, It utilizes inexpensive, industry‐standard servers. The key features of Hadoop are Cost effective system, Scalability, Parallel processing of distributed data, Data locality optimization, Automatic failover management and supports large clusters of nodes.
How Hadoop Works:
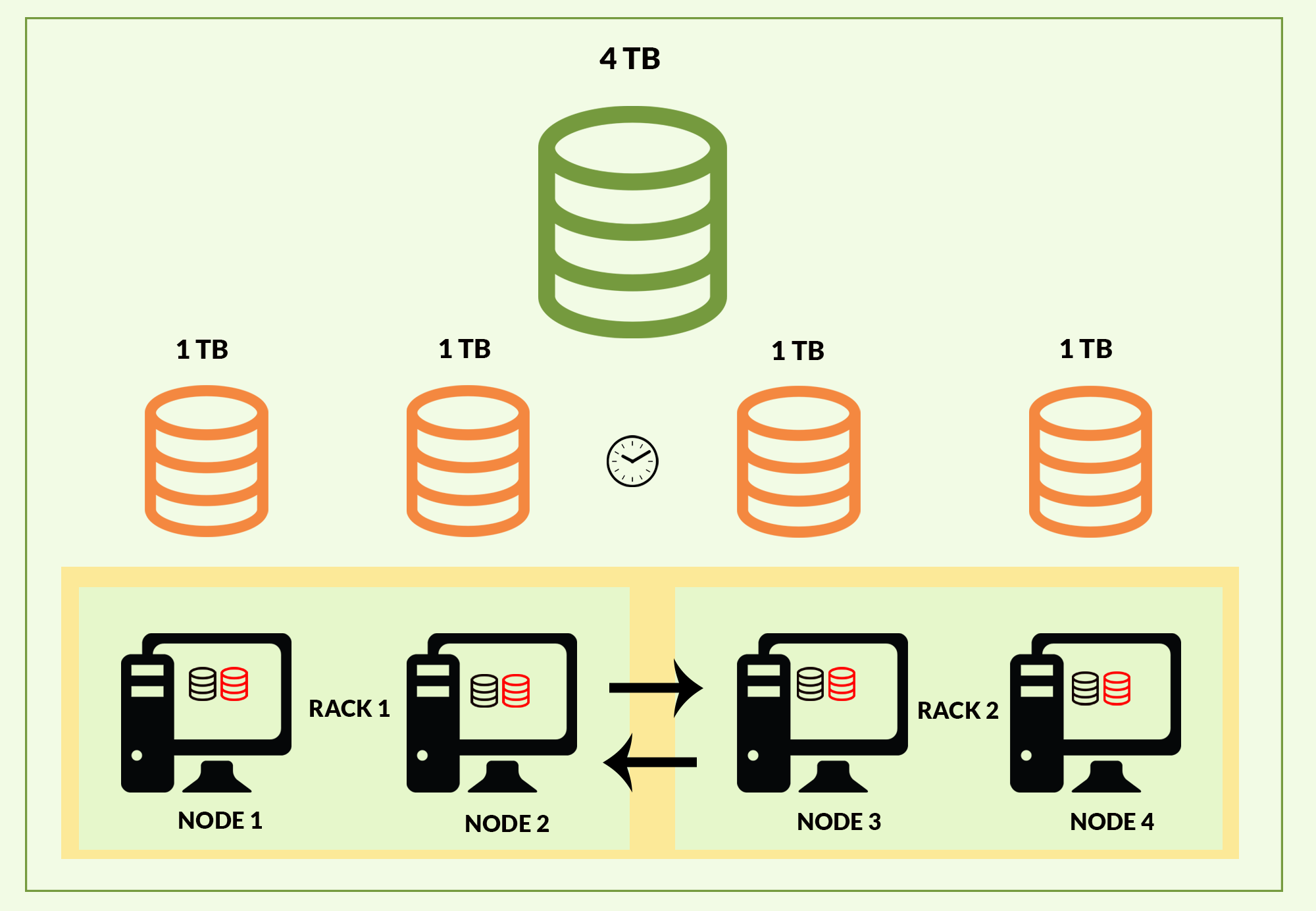
The Hadoop frameworks are comprised of two main core components i.e. HDFS and MapReduce framework. The Hadoop framework divides the data into smaller chunks and stores each part of the data in the separate node within the cluster. By doing this, the time frame to storing the data onto the disk significantly reduces. In order to provide high availability, Hadoop replicates each part of data on to other machines that are present within the cluster. The number of copies it replicates depends on the replication factor. The advantage of distributing this data across the cluster is that while processing the data it reduces a lot of time as this data can be processed simultaneously. The Figure shows the Hadoop working model for 4TB of data in 4 nodes of the Hadoop cluster.
Check out the below video: