

DevOps means a lot of different things to different people. A few take it as "Operations and Development Collaboration", and a few take it as "Code as Infrastructure" or "Culture". The term "DevOps" has emerged from the collision of two major trends- "Agile Infrastructure/Operations" and understanding the value of “collaboration between Operations and Developers” throughout the development life cycle.
Interview questions on DevOps
1) What is DevOps?
DevOps is a transformational development strategy that is adopted to remove the clumsiness between traditional development and operations. Without sacrificing the quality of the product delivered, it seeks for an increased speed of application delivery. DevOps removes development constraints, implements automation and creates a feedback loop from operations to the development team. In simple terms, DevOps is a mindset to deliver applications quickly with no compromise in quality.
3 Pillars to support the principles of DevOps Development:
-
Deliver Business Value predictably and incrementally.
-
Utilize proven technologies and patterns.
-
Apply appropriate rigor.
2) What are the Advantages of using DevOps?
In the DevOps model, development takes place in small and frequent development cycles based on sprint size that are likely to end in two to four weeks; so that any changes in business needs can be easily incorporated into the upcoming sprint.
In the DevOps approach, much of the solution is composed using existing reusable APIs, reliable third party services, etc. This helps in reducing the development time by making the most of the new code, required only in integration and customization.
3) What is Extreme Programming (XP)?
Extreme Programming commonly referred to as XP is one of the most popular agile methodologies, which executes software development. XP rules are designed to focus more on customer satisfaction. It empowers developers to respond confidently to requirement changes through smaller iterations. XP emphasizes teamwork as managers, customers and developers work as equal partners in a collaborative team. Most of the companies use XP in their DevOps Journey.
4) What is Pair Programming?
Pair programming is one of the engineering practices of Extreme Programming rules. In this practice two programmers work on one computer, on the same design/algorithm/code/test.
One programmer acting as a “driver”, and the other acting as an “observer” who continuously watches/monitors to identify problems. Both roles can be exchanged at any point of time without any handoff.
5) What are the advantages of Pair Programming?
Pair Programming helps in raising discussions from two different points of view, which in turn help in increased understanding of code/algorithm/design/test.
6) What is Test Driven Development (TDD)?
Test Driven Development is one of the core agile and DevOps practices, which is more helpful in quick iterations and continuous integrations. In this method, test cases become the key to development process. This method ensures that problems are identified quickly, which helps manage risk elegantly.
TDD is a practice where you write code to address a failing test case. It is not only considered as a testing methodology, but also as a design and development methodology.
TDD starts with taking customer requirements, writing test cases and running the code against test cases. Test Cases fail as there is no code to address the test scenario; then, you write a simple code to PASS the test case.
7) What are the advantages of Test Driven Development?
As TDD first starts with the test case, the quality of code is increased as there will be one or more test cases for all the functionalities.
-
Refactoring code can be done confidently.
-
Eventually, the complete code in your application is well tested; since, it is constructed to address all the test cases.
-
Code turns more modular and flexible as developer is addressing all the test cases by coding in smaller units.
Note: TDD is only as good as its tests. If the tests are not reflecting the requirements, code cannot reflect the requirements.
To know more about Test Driven Development, you can refer to-
‘Test Driven Development: A Practical GUIDE – David Astels.’
8) What is a build?
Build is a process in which the source code is put together to verify whether it works as a single unit. In the process of build creation or generation, the source code will undergo compilation, testing, inspection and deployment. Usually, build generation process is completely automated in a way that a single command does everything.
9) What is Continuous Integration?
Continuous delivery is an important aspect to be understood when it comes to DevOps. On the path to Continuous delivery, Continuous Integration is a critical step. Continuous Integration defines when an automated build has to be generated. CI is one of the software development practices where member of the team frequently integrates their code, which then undergoes build generation process verifying the code written by individuals. Generally, each member will integrate his/her code once in a day. Each integration is verified and tested as part of build generation process.
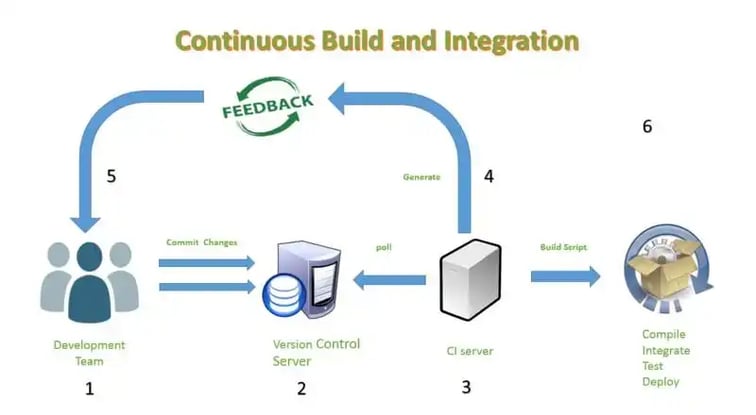
-
The developer commits his changes.
-
CI server polls the Version Control repository every few minutes for changes.
-
CI server picks up changes and kicks off the build script.
-
Build scripts run, and the CI server generates feedback based on the output of the build script.
-
Feedback is checked to ensure that the build has run successfully; if not, the developer addresses the issue.
-
CI server keeps polling the Version Control Repository for more changes.
10) What are the benefits of Continuous Integration?
Software is deployable at any time. Having an immediate feedback mechanism helps the developers to act if there are any issues quickly.
Software quality increases as defects are prevented from being integrated.
Due to automated inspection and testing, software health can be tracked easily.
Results of the builds are published, highlighting the test cases that have failed.
Accountability of code is always recorded.
11) What are Design Patterns?
In simple terms, Design Patterns are the solution to problems faced by developers- they represent the best practices that are used by developers. Design Patterns help an inexperienced developer to learn easily and quickly. Design Patterns have standard terminologies addressing specific scenarios.
There are mainly 3 types of Design Patterns:
-
Creational: addresses design problems.
-
Structural: simplifies relationships between objects.
-
Behavioral: simplifies how objects interact with each other.
12) What is Component Based Development?
In the CBD approach, unlike the traditional way of development, developers look for existing well-defined, tested, and verified components to compose and assemble them into a product instead of developing it from scratch.
Example:
Continuous Deployment
1) What is Continuous Deployment?
Continuous Deployment is majorly about instrumenting the most important steps within the project life-cycle when moving code from quality assurance step to production environment. Continuous Deployment is a critical capability to enable in the continuous delivery pipeline. There are several patterns that enable the nature of Continuous DevOps deployment.
2) What is Blue/Green Deployment Pattern?
Blue/Green Deployment pattern addresses one of the most important challenges faced by automatic deployments; i.e., the cutover from final stage of testing to live production. Ensuring this cutover happens quickly is the best way to reduce system downtime.
In Blue/Green Deployment approach, the team first ensures two identical production environments; but, only one among them is LIVE at any given point of time.
The LIVE environment is considered as Blue environment, and as the team prepares the next release of their software, they conduct their final stage of testing; considering it as Green environment. Once the team completes their final round of testing, they utilize some sort of tools which enable the user requests directly to the new Green environment. The Blue environment is considered as idle. The basic idea here is to easily switch between the environments.
Advantages:
-
A stand-by production node is always running.
-
Allows rollback testing with every release.
-
Rollback option is always available.
Disadvantages:
-
Cost of maintaining 2 production environments.
-
Databases are a challenge that may require refactoring.
3) What is Canary Release?
Canary release is a pattern that reduces the risk of introducing a new version of software into production; this is done by making it available in a controlled manner to a subset of users before making it available to the entire user set.
In this pattern, the team deploys the new version only to a subset of the infrastructure, where there are no user request routed. Once the team is happy with the performance tests, they start routing a selected group of users to the application. As and when they feel confident, the company can release more servers as the team also routes more user requests.
Advantages:
-
Slow Ramp-up/down helps in monitoring/metrics.
-
Ability to do capacity testing.
-
Very safe rollback strategy.
Disadvantages:
-
Managing more than one software at a time.
-
Hard to work on distributed software.
4) What are the Tools and Services available to practice DevOps?
Here are the famous DevOps tools and services; they can be categorized as follows-
Applications/Platforms:
-
Eclipse
-
Netbeans
-
IBM BlueMix
-
Smart Cloud
-
Catalyst, etc.
Infrastructure/Configuration:
-
Chef
-
Ansible
-
Puppet Labs
-
StackEngine
-
Docker, etc.
Virtualization:
-
OpenStack
-
VMWare
-
SoftLayer
-
Vagrant
Build Automation tools:
-
Apache Ant
-
Apache Maven
-
Worklite
Version Control Tools:
-
Git
-
Apache Subversion
Continuous Integration Tools:
-
Jenkins
-
Tavis CI
-
TeamCity
Continuous Testing
1) What is the importance of Continuous Testing?
Continuous Testing actually means testing earlier across the software development life cycle by enabling ongoing testing and verification of the code; so that it ensures the code actually functions and performs as designed.
One needs to look at Continuous Testing through the lens of DevOps, creating a safety net for teams to develop, test, and release new features without compromising on quality (here are some resources to help you navigate through cloud service providers).
This can be achieved by adopting and practicing automated testing, test data management, CI, and much more.
Two Principles of Continuous Testing are Test Early and Test Often.
2) What is Functional Testing and Non-functional Testing?
Functional Testing mainly targets the business goals as a way of ensuring that, within the code design and features, the product meets the customer’s business requirements.
On the other hand, non-functional testing focuses on performance, security, compatibility, usability, user experience, resource utilization, etc.
3) What are the foundational pillars of DevOps Testing?
The primary pillars of DevOps testing are:
-
Embrace testing early and ensure production readiness at all times.
-
Utilize proven technologies and patterns.
-
Apply appropriate rigor.
4) What are white box and black box testing?
Black box testing is where the tester does not know anything about the internal structures of the application. On the other hand, box testing is where the tester knows about the structure and designs of the product.
White box testing is done at the unit and component level of testing, whereas black box testing is done at the system and acceptance level of testing.
White box testing essentially needs some programming languages, whereas black box testing may or may not need any programming skills.
Read more Top 30 Interview Questions and Answers on Angular 5
5) What are the types of testing frameworks available in the market?
There are four types of testing frameworks available in the market. They are-
- Modular Testing Frameworks: Aligns itself closely to the module structure of the application that is targeted for testing. Individual modules have their own test scripts and can be built hierarchically into larger and larger sets.
Advantage: It is very easy and quick going.
Disadvantage: Data gets embedded in test scripts, which in turn makes it tough to maintain.
- Data-driven Testing Frameworks: Test case logic is defined in the test scripts and input test data is kept outside of the test scripts. Test data can be in Excel files, CSV, JSON, etc. When test suite is run, the test data is loaded into variables in the test scripts.
Advantage: Requires less number of test scripts over modular framework.
Disadvantage: There still exists tight coupling between data and scripts.
- Keyword Driven Testing Frameworks: It requires development of keywords and test data tables independent of test automation tool used to execute. Tests can be designed with or without the application.
Advantage: More flexible as both Data and Keywords can be reused across the scripts.
Disadvantage: Flexibility comes at the cost of complexity.
- Hybrid Testing Frameworks: Tends to take the best of the other frameworks mentioned above and combines to a structured framework.
Advantage: Incorporates all the testing framework approaches.
Disadvantage: Very complex.
6) Name some automation testing frameworks you know.
Selenium, QTP, Appium, IBM Rational Functional Tester, Robot Framework, Cucumber, Nose, etc.
7) What is the Resilience Test?
Tests that ensure recovery without data and functionality loss after a failure are called Resiliency tests. Here are the examples of Resilience test tools.
Hystrix: An open source tool, which has latency and fault tolerance libraries, designed to isolate points of access to remote systems and services.
Chaos Monkey: Developed by Netflix to randomly disable parts of the system and simulate production failures.
Configuration Management
1) What is Configuration Management?
The process of storing, modifying, assessing and identifying all the artifacts of a project and understanding their interconnectedness is called Configuration Management. Configuration Management strategy is key for any project because it is the plan that outlines how you will manage the changes within your project. Configuration Management is synonymous with Version Control.
2) What is Version Control?
Version Control is an application that keeps track of different versions of your project as well as its artifacts and components. Storing files on USB drives is not version control. People think that version control is only for code, but it's not. Every single artifact that is related to your project- source code, deployment scripts, test scripts, database scripts, documentation, libraries and configuration files, etc., is included.
There are two types of Version Control Systems:
-
Centralized Version Control System
-
Distributed Version Control System
3) What do you know about Git?
Git is a distributed version control system, it plays an important role in achieving DevOps. Git is free software distributed under the terms of GNU General Public License V2.0.
Advantages:
-
Git is free and open-source software.
-
There is no single point of failure.
-
No need of high-end servers.
-
Git has the hash key mechanism to authenticate users.
-
Easy and Fast
-
As there are multiple copies of the code, the probability of losing data is very less.
4) How does Git work?
Git is a distributed version control system in which, the source code resides in the central repository server. Developers clone the entire repository onto their workstation, and create branches to modify/add new code. Once the developer is done with coding, he can commit and push the code to the central server.
Basic Workflow:
Step 1: User Clones the entire repository onto his work station generally called as Local Repository.
Command: git clone <url of git repo>
Step 2: User will checkout a new branch and start adding/modifying the code. By default, git has a master branch.
Command: git checkout –b <new branch name>
Step 3: User adds those files to the staging area and performs a commit operation to move those files from staging area.
Command: git add <file name>
git commit –m <message>
Step 4: If everything is fine, user performs PUSH operation to store his changes permanently in the central repository. If the user finds anything wrong, he can correct the last commit and push the changes to the repository.
Command: git push
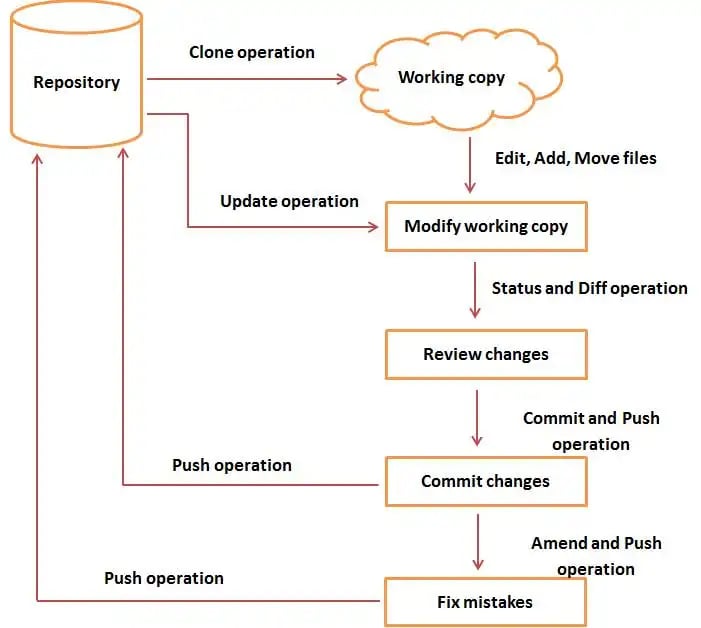
Image Source: http://www.diagrams.science/git-diagram-tutorial/
5) What is a branch in git?
The branch is a new line of development. The purpose of creating a branch is to start adding/modifying. One can create multiple branches and switch between them.
Commands :
To create a new branch:
$] git branch <new_branch_name>
To list the branch:
$] git branch
To check out a new branch:
$] git checkout <new_branch name>
To create and checkout a new branch:
$] git checkout –b <new_branch_name>
To delete a branch:
$] git branch –d <branch name>
6) What is git stash?
Let’s suppose a user is working on one of the features, and suddenly a customer escalates an issue. Users may have to keep their work aside and resolve the customer’s issue as a high priority. The user cannot commit his partial code and cannot throw away his changes; in such cases, git provides a solution with stash operation. Git stash operation moves all the modified files, stages, and changes and pushes them onto a stack of unfinished changes that a user can get back at any time.
Commands:
$] git stash
To see the list of stash
$] git stash list
To get back the stashed files to the current working directory
$] git stash pop
Learn more about Top 40 Spring Interview Questions and Answers (Updated for 2018)
7) What is git rebase?
After creating a personal branch and adding and modifying files, what if the master branch is updated and your branch becomes stale? In such scenarios, one can use git rebase. Git rebases command e will replay the changes made in your local branch at the tip of the master, allowing conflicts to be resolved in the process.
8) What is git stash drop?
To remove stashed items, the git stash drop command is used. By default, this command deletes the last stashed items. We can also delete a particular stash item. The Git stash list command lists all the stashed items. We can select the stash item to be removed and pass its name to the stash drop command.
9) How do you create a new repository in git?
Create a project directory and run “git init” under that directory. It creates a .git directory in the project directory.
10) How can one know the branches have already merged into the master branch?
-
git branch --merged master lists branches merged into master.
-
git branch --no-merged lists branches that have not been merged.
Conclusion
As you know that practicing DevOps includes many tools and techniques. Interview questions will depend on what environment (Tools and Technologies) you employed in your project.
ALL THE BEST!



