
The Dark Web: What is it and how can you access it
Unless you’ve been living under a rock, chances are good that you’ve heard of the “dark web”. Many view the dark web as something sinister that is all about online crime and illegal content – like an online “Mos Eisley” (a “...wretched hive of scum and villainy.”)
It turns out that the perception of it and the reality are (as is often the case with these things) quite far apart. In fact, the vast majority of deep web and dark web content is - though hidden from normal view - perfectly innocuous. However, because of the fact that the dark web is anonymous, private, and difficult to eavesdrop on, attackers and cybercriminals do use it as part of their toolkit to commit cyberattacks.
This means that, from a defense standpoint, it is valuable for us to understand something about it so that we can understand how it might play into the threat scenarios that we need to keep our businesses defended against.
With that in mind, let’s do a deep dive on the dark web: what it is, how it works, and how you might use your awareness of it to better your security posture.
"Dark Web" vs. "Deep Web"
The first concept that is useful to understand is the so-called “deep web.” By deep web, we just mean the portion of the Internet that is unindexed – i.e., not pointed to by sites like Google, Bing, or other search engines.
Deep Web - The Library
Probably the easiest way to understand this is through an analogy to the physical world – one that everyone will be familiar with. Imagine for a moment a physical book in a library. Library visitors wishing to find that book go to a central index – for the sake of this example, let’s assume the library has an “old school” card catalog that records information about the book’s location so that anyone wanting to read it can go to the shelves and retrieve it. In that situation, what happens if someone removes the book’s entry from the card catalog? Say some prankster removes the card and tears it up.
As we know, the book doesn’t disappear – it’s still in the same place it always was. But since the index record has been lost, new visitors don’t know either that the library has a copy or where it might be on the shelves. Someone who knew exactly where that book was though could go right to it and read it just like they always have.
This is almost directly analogous to data (in some cases web pages but also other types of data as well) on the Internet. For web content, we’re used to searching engines “crawling” or “spidering” content, and creating an index so we can find what we want. Normally, that’s advantageous since most sites want the content to be found by as many users as possible.
But what happens if there’s data that search engines don’t know about? For example, a page that nothing else links to. In this case, when search engines crawl through looking for content to index, they won’t find this page since nothing else links to it. The data is still there – just not indexed.
Now, what’s important to note about the deep web is that it potentially includes a lot of data. In fact, you might think about the deep web as a massive “soup” of data including everything from web pages to binary files to media (video and audio) to unstructured data and beyond (also consider checking out this career guide for data science jobs). It includes pages used only by developers to test new content, new sites that haven’t been indexed, data on miscellaneous servers that happen to be Internet-facing, and so on. In fact, much of “deep web” data isn’t placed there purposefully.
What is the “dark web”?
If the deep web is unindexed information, the dark web is that portion of that is accessible only via specific, defined channels and protocols. Now, while any content or data that is hidden from view in this way is technically what some call a “darknet”, what people usually mean when they talk about the Dark Web are pages and data accessible via Tor.
Tor, originally created as “The Onion Router”, is open-source software that implements a specific routing protocol that (among other things) allows users to exchange data anonymously. Tor works by creating virtual “pathways” through a global network of routers where each node in the path only knows about the nodes immediately in front of and immediately behind them in the link. Meaning, nobody in the chain – even the routers themselves – know the source, destination, and content at the same time.
To illustrate this, take a look at the diagram below.
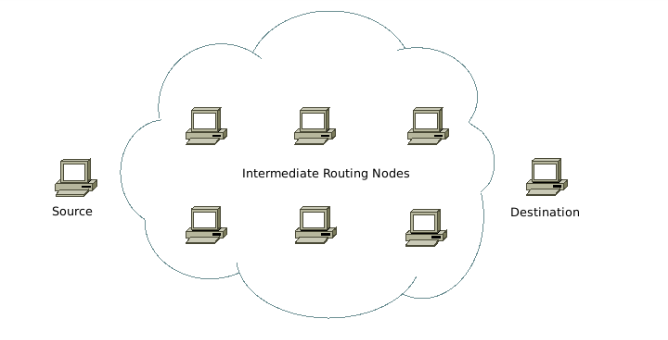
Shown on the graph are three main elements:
- A point of origin (labeled “source”)
- A destination (labeled “destination”)
- A number of intermediate, router nodes (labeled “intermediate routing nodes”)
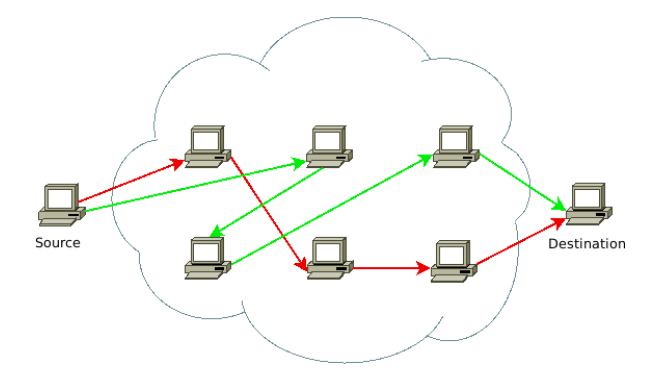
The source routes traffic through each of the routing nodes to reach the destination, taking a random path along the way. One connection might connect through using a given combination of nodes and another might do so with an entirely different set of nodes. For example, in the diagram below, we’ve overlaid two of the possible paths that traffic might take (one in red and one in green). Yet a third connection might take a completely new path.
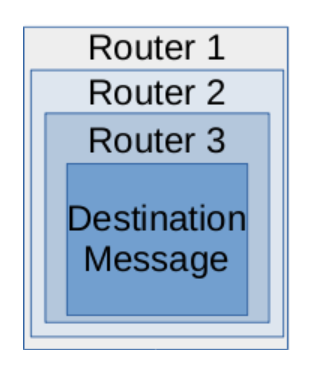
The way that this is technically enforced is by using encryption and creating encrypted “layers” for each node. The message is encrypted such that each node along the chain can decrypt only a portion of the data - enough for them to know where the next hop along the path is. As each router decrypts its layer and discovers the next “hop” along the path, it forwards the contents along.
Like the layers of an onion, each layer needs to be stripped away to reveal the underlying message at the center - and since each hop only knows its immediate predecessor and successor in the chain, only the first router in the chain knows the source (but not the destination) and only the last router in the chain knows the destination (but not the source).
Illustrated graphically, the message is encapsulated multiple times: each encapsulation enabling a router to get to the next hop.
Like Matryoshka Dolls
A way to think of it is by an analogy to the physical world. If I wanted to mail a letter to you, how could I do it in such a way that would keep the post office from knowing that you and I are communicating? By analogy to this strategy, I could pre-address a letter to you, and put that letter inside another letter to someone else (let’s call them “Friend 1”) along with instructions to unpack and mail the contents.
Then I put the letter to Friend 1 inside another letter addressed to yet another person (“Friend 2”) along with instructions to mail the contents. I could repeat this as many times as I like to create a package that, when mailed, would eventually get to you but where intermediate people along the way (not to mention the postal service) wouldn’t know that you and I are communicating.
The post office can tell that I’m communicating with the first person in the chain - and your postal carrier knows you are communicating with the last person - but there’s no easy way to tell that it’s really you and I talking to each other.
Implications
Now that you know the fundamentals of what the dark web is and how it works, let’s talk about how attackers might use it. First and foremost, they can use the above strategies to communicate in ways that - because they’re private - are “safer” for them from law enforcement in the event that they wish to conduct criminal activity.
For example, if they want to share data about potential victims, exchange tools or data, buy and sell illicit services, etc. Given this, you will find organizations out there that specialize in “dark web monitoring” - i.e., services that (through either manual or automated means) look for information on the dark web where your organization might be involved. For example, if an attacker compromises your environment, steals information about your business or customers, and tries to store, sell, transfer, or otherwise exchange that information via an attacker community. For example, you might look for information about user accounts that have been compromised appearing in these channels.
Another implication is that there could be those on your internal network that are using Tor to access resources that they shouldn’t while they are at work - for example accessing inappropriate or illegal content hidden by others. In this situation, you might choose to disallow such traffic unless individuals can provide authorization for why they require such access to perform their jobs (also consider checking out this career guide for cyber security jobs).
The point is, understanding what the dark web is and how it works makes it a lot less scary. Additionally, there is quite a bit of hype and hyperbole about the dark web (and deep web) being exclusively used for criminal activity. Is there a criminal activity that happens on the “dark web”? Sure. Hopefully though, as you can see by now, just because the content is not indexed (deep web), that does not make it criminal - and just because someone is using Tor, that doesn’t mean it’s definitely criminal either.
Want to know more about cybersecurity? Check out our cybersecurity guide.